Razvoj orodja za glasovno programiranje (Nina Sangawa Hmeljak)
Development of a voice programming tool
Cilj diplomske naloge je izdelava orodja za pisanje in urejanje kode računalniških programov z uporabo glasu. Predstavljenih je nekaj primerov obstoječih orodij za kodiranje z glasom, nato postopek ustvarjanja orodja Slo-handsfree-coding za glasovno programiranje v slovenščini. Ustvarjen je bil tudi poseben jezik oz. format ukazov za upravljanje tega orodja po zgledu že obstoječih orodij. Orodje je realizirano v obliki razširitve za urejevalnik kode Visual Studio Code, ki za pretvorbo govora v besedilo uporablja odprtokodni razpoznavalnik iz projekta RSDO. Pridobljen zapis to orodje analizira in glede na vsebino izvede ukaz. Na koncu so še rezultati in povratne informacije testiranja izdelka.
Ključne besede
programiranje, zaznavanje govora, programiranje z naravnim jezikom, glasovno programiranje
programming, speech recognition, natural language programming, voice coding
S poizvedovanjem obogatene tehnike generiranja pravnih besedil (Rok Mušič)
Retrieval-augmented generation of law texts
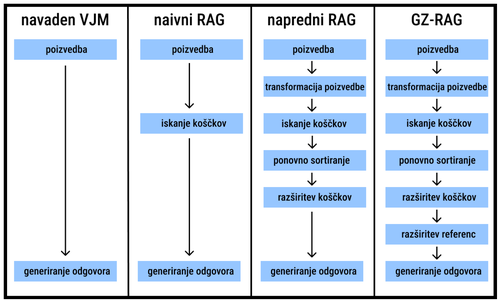
Slovenska zakonodaja je obsežna in pravni delavci porabijo veliko časa vsak dan za iskanje ustrezne literature. V ta namen smo raziskali uspešnost velikih jezikovnih modelov (VJM) kot pravnih asistentov. VJM-ji so uspešni v številnih nalogah, a zahtevna domenska vprašanja so ena izmed njihovih večjih pomanjkljivosti; pogosto pride do halucinacij. S poizvedovanjem obogateno generiranje besedil (RAG) je tehnika, ki zaobide pomanjkanje domenskega znanja VJM-jev tako, da na podlagi vprašanja v zakonodaji najde vsebino, s katero lahko pravilno odgovori na vprašanje. Z najdenim znanjem VJM pravilno odgovori in ne halucinira. Raziskali in implementirali smo več različnih tehnik RAG. Vse metode smo preizkusili na ročno izdelani testni množici, ki vsebuje 4 testne scenarije, s katerimi preverimo, kako uspešne so metode v različnih situacijah. Naprednejše različice RAG-a, napredni in modularen RAG, kažejo dobro uspešnost pri direktnih vprašanjih, a nižjo uspešnost za bolj splošna vprašanja kot so npr. dejanski primeri.
Ključne besede
velik jezikovni model, s poizvedovanjem obogateno generiranje besedil, obdelava naravnega jezika
large language model, retrieval augmented generation, natural language processing
Jadranje je iz leta v leto bolj priljubljen hobi in način dopustovanja. Jadranje je močno povezano z navtiko, ki pa na področju tehnologije ne napreduje in je veliko prostora za napredek in velika potreba po modernizaciji. Diplomska naloga je namenjena izdelavi aplikacije, ki bi jadralcem omogočila lažji postopek priveza v zalivih z bojami. V diplomski nalogi predstavimo problem sedanjega načina privezov in predstavimo rešitev, opišemo razvoj zalednega in čelnega dela aplikacije. Tehnologije, ki jih uporabimo so MySQL baza, iz katere aplikacija pridobiva podatke preko aplikacijskega programskega vmesnika - API, izdelanega s pomočjo tehnologije Node.js in Express.js. Čelni del pa je razvit s pomočjo odprtokodne knjižnice React.js.
Razvoj odprtokodnega ogrodja za obdelavo naravnega jezika (Miha Krištofelc)
Developing an open source framework for natural language processing
V diplomskem delu se bomo osredotočili na razvoj aplikacije za gradnjo cevovodov z namenom obdelave naravnega jezika. Naš cilj je raziskati trenutne rešitve na trgu in vključiti izboljšave v razvoj nove aplikacije, prilagojene raziskovalcem in splošni javnosti, ki jo zanima ONJ. Za preverjanje uporabnosti aplikacije bomo izvedli uporabniško testiranje, funkcionalno testiranje ter tudi testiranje zmogljivosti. Pri razvoju aplikacije bomo uporabili ustrezna razvojna orodja, kot so Django za razvoj zalednega dela, NextJS za razvoj čelnega dela in Docker za upravljanje z vsebniki. Poleg tega bomo za nadzor različic in varnostno kopiranje kode uporabljali program Git. V zaključku bomo predstavili ocene uporabniške izkušnje, oceno učinkovitosti aplikacije in splošne rezultate diplomskega dela.
Ključne besede
cevovodi, obdelava naravnega jezika, docker, vsebniki, podatkovni inženiring
Pipelines, Natural language processing, Docker, Containers, Data engineering
Pregled in uporaba grafnih podatkovnih baz s podporo SPARQL (Domen Antlej)
Review and usage of graph-based databases with SPARQL support
Semantične podatkovne baze so poseben tip grafne podatkovne baze, ki omogoča hrambo semantičnih podatkov. Namen diplomske naloge je predstavitev področja semantičnih baz in prikaz primera uporabe s konkretnimi testnimi podatki. Vsebinsko je diplomska naloga razdeljena na tri dele. V prvem delu je predstavljeno področje semantičnih baz in tehnologije, ki jih podpirajo. V drugem delu izvedemo primerjavo nekaj popularnih baz in izberemo eno, ki bo uporabljena kot primer uporabe. V tretjem delu izvedemo pretvorbo relacijskih podatkov v semantične podatke in jih uporabimo z izbrano semantično bazo. V zaključku so predstavljene ugotovitve diplomske naloge.
Ključne besede
semantični splet, podatkovne baze, SPARQL, ontologije, pretvorba podatkov
semantic web, databases, SPARQL, ontologies, data conversion
Podatkovne baze sestave živil (PBSŽ) so temeljno orodje pri raziskavah na področju prehrane, ocenah hranilnih vrednosti in sorodnih domenah (npr. zdravje, okolje). Vendar se, tako kot druge znanstvene discipline, tudi področje prehrane in sestave živil spopada s težavo manjkajočih podatkov. To lahko znatno zmanjša natančnost in zanesljivost analiz, ki temeljijo na strukturi živil, saj vpeljuje element dvoumnosti in s tem omejuje njihovo uporabo. Za rešitev tega problema so bile predlagane različne metode za dopolnjevanje manjkajočih podatkov. Najlažji in najpogostejši pristop je izračun povprečja oziroma mediane iz razpoložljivih podatkov v isti bazi ali pa izposoja vrednosti iz drugih. Vendar pa lahko takšne preproste metode povzročijo znatne napake. V tem diplomskem delu se raziskuje uporaba modela ComplEx iz knjižnice Ampligraph, ki temelji na vektorskih vložitvah grafa znanja za dopolnjevanje manjkajočih vrednosti v PBSŽ. S pristopom opisanim v tem delu lahko model zajame temeljno strukturo in odnose med podatki, kar omogoča natančno dopolnjevanje manjkajočih vrednosti. To dodatno potrjujejo rezultati tega dela, saj so primerljivi s tistimi najsodobnejših modelov. Uporaba predlagane metode bi lahko v prihodnje privedla do natančnejših in zanesljivejših analiz na področju prehranskih raziskav.
Ključne besede
podatkovna baza sestave živil, hranilne vrednosti, manjkajoči podatki, strojno učenje na grafih, vložitev grafa znanja, analiza in raziskovanje podatkov, dopolnjevanje manjkajočih vrednosti, ampligraph
food composition database, nutrient values, missing data, graph machine learning, knowledge graph embeddings, data exploration, missing value imputation, ampligraph
Uporaba metod obdelave naravnega jezika za uvrščanje shem programskih vmesnikov v enoten podatkovni model (Matic Conradi)
Use of natural language processing methods for classification of application programming interface schemas into a unified data model
Cilj te raziskave je razviti sistem, ki je zmožen klasificirati sheme objektov JSON, ki izvirajo iz različnih sistemov za digitalizacijo procesov, ter najti ujemanja s predstavitvami domenskih entitet platforme DevRev. Glavni izziv, s katerim se soočamo, leži v raznolikosti struktur teh objektov, kar zahteva uporabo algoritmov za obdelavo naravnega jezika.
Ključne besede
obdelava naravnega jezika, uvrščanje shem, Word2Vec, BERT, GPT, veliki jezikovni modeli
natural language processing, schema classification, Word2Vec, BERT, GPT, large language models
Pregled in analiza semantičnih (SPARQL) podatkovnih baz (Anja Ostovršnik)
Review and analysis of semantic (SPARQL) databases
Semantične baze so posebna vrsta podatkovnih baz, ki omogočajo shranjevanje in poizvedovanje podatkov na način, ki upošteva njihov pomen in medsebojne odnose. Namen diplomske naloge je predstavitev in primerjava nekaj najbolj razširjenih rešitev na področju semantičnih baz. Vsebinsko je diplomska naloga razdeljena na dva dela. V prvem delu so opredeljeni kriteriji za primerjavo različnih ponudnikov semantičnih baz ter opis in primerjava njihovih rešitev. V drugem delu so opisani načini testiranja in načrt implementacije baz. V praktičnem delu izvedemo testiranje po zastavljenih testnih scenarijih. V zaključku so podane ključne ugotovitve glede predstavljenih semantičnih podatkovnih baz.
Prepoznavanje imenskih entitet na domenskih besedilih iz farmacije (Benjamin Kovač Keber)
Named entity recognition in pharmaceutical domain texts
Prepoznavanje imenskih entitet je ena od nalog problema procesiranja naravnega jezika. Gre za označevanje besed in besednih zvez z oznakami v naprej določenih tipov imenskih entitet. Primeri uporabe prepoznavanja imenskih entitet so klasifikacija vsebine za ponudnike novic, učinkoviti iskalni algoritmi, priporočanje vsebine, organizacija člankov in podpora strankam. Preučili smo problem prepoznavanja imenskih entitet na domenskih besedilih iz farmacije. V ta namen smo uporabili štiri različne metode in za učenje modelov uporabili dva korpusa (CHEMDNER in n2c2), ki imata ročno označene imenske entitete iz področja farmacije (in kemije). Modele smo evalvirali tudi na besedilih, ki smo jih sami ročno označili. Najbolje se je odrezal model BERT. Za praktično uporabo pa bo verjetno potrebno v modele vložiti še nekaj truda za izboljšave.
Ključne besede
procesiranje naravnega jezika, prepoznavanje imenskih entitet, farmacija
natural language processing, named entity recognition, pharmacy
Primerjava metod za avtomatsko ekstrakcijo podatkov iz spleta (Gašper Martič)
Comparison of methods for automatic Web data extraction
Namen diplomskega dela je pregledati in ovrednotiti obstoječe metode za avtomatsko ekstrakcijo podatkov s spletnih strani. Tovrstne metode preko analize večjega števila podobnih spletnih strani avtomatsko generirajo ovojnico, ki je sposobna s spletne strani izluščiti podatke, tudi če se struktura strani s časom rahlo spremeni. Rezultati diplomskega dela ponujajo enostaven pregled nad različnimi metodami za pridobivanje podatkov s spletnih strani. To je lahko koristno za uporabnika, ker iz spletne strani izloči moteče oglase in navigacijske menije, ki odvračajo pozornost od vsebine. Kvaliteta posamezne metode se meri v hitrosti in sposobnosti odstranjevanja nerelevantnih podatkov ter ohranjanju tistih, ki so pomembni za dojemanje vsebine. Izvajanje samih metod je avtomatizirano s pomočjo programa v jeziku Python, ki ga lahko poganjamo iz ukazne vrstice. Uporabljani sta obstoječi implementaciji metod RoadRunner in Webstemmer, prikazani pa so rezultati njunega delovanja na petih slovenskih spletnih medijih. Poleg tega je implementirana tudi polavtomatska metoda pridobivanja podatkov s pomočjo ogrodja Scrapy, da lahko vidimo rezultate in kompleksnost v primerjavi s popolnoma avtomatsko metodo.
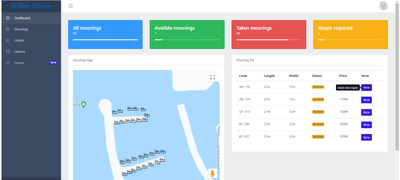
Informacijski sistem za upravljanje marin (Lovro Jevnikar)
Management information system for marinas
V diplomski nalogi se bomo ukvarjali z izdelavo informacijskega sistema za podporo marin. Končni izdelek bo spletna aplikacija, izdelana z orodjem VueJS. Rešitev bo digitalizirala postopek upravljanja marine. Reševali bomo problem urejanja oziroma popravila privezov, hranjenje informacij o trenutnem stanju marine in tudi možnost plačila oziroma rezervacije le teh. Za izboljšano uporabniško izkušnjo bomo aplikaciji dodali interni forum za komunikacijo med strankami znotraj marine. Pri izdelavi bomo uporabil storitve Amazon web services, Google maps API, Bootstrap in ostale Vue komponente. Za izbrano tematiko smo se odločili, ker po pregledu področja nismo našli primerne rešitve za omenjeni problem.
Zasnova ogrodja za izvajanje metod za procesiranje naravnega jezika (Nik Hrovat)
Design of a framework for execution of natural language processing methods
V diplomski nalogi bomo predstavili predlog svojega ogrodja za procesiranje naravnega jezika. Cilj procesiranja je, da računalnik razume vsebino dokumentov, izloči informacije iz besedila in dokumente organizira ter razvrsti. Opisali bomo nekaj metod, ki se uporabljajo pri procesiranju naravnega jezika. Ob tem bomo primerjali še nekaj obstoječih ogrodij in knjižnic ter najboljšo tudi podrobneje predstavili na podatkovnem modelu. Na podlagi analize obstoječih ogrodij in knjižnic bomo predstavili tudi naš podatkovni model, ki ga bomo testirali z nekaterimi metodami procesiranja naravnega jezika in ga tudi grafično prikazali.
Ključne besede
NLP, procesiranje, naravni jezik
NLP, processing, natural language
Viri
Diplomsko delo je v popravkih.
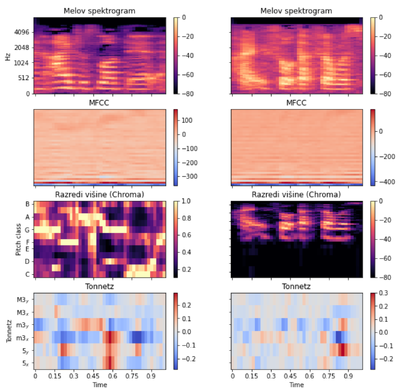
Vpliv govorjenih posnetkov na analizo sentimenta njihovih transkriptov (Martin Jurkovič)
Sentiment analysis of voice recordings and their transcripts
Analiziranje sentimenta s pomočjo metod strojnega učenja je ena bolj raziskanih tem na področju obdelave naravnega jezika. Večina raziskav se osredotoča na analiziranje pisanega besedila kot so članki ali knjige. V primeru govorjenega besedila pa se poleg transkriptov posnetkov lahko analizira tudi sama zvočna datoteka posnetka. V diplomski nalogi smo raziskali in naučili različne modele strojnega učenja za analizo sentimenta na transkriptih posnetkov, nato pa poskusili izboljšati rezultate tekstovnih modelov z modeli, zgrajenimi na podatkih pridobljenih iz zvočnih datotek posnetkov. Za združevanje ter izboljšanje napovedi besedilnih in zvočnih modelov smo uporabili metodo zlaganja modelov. V delu smo raziskali in implementirali celoten cevovod za predprocesiranje podatkov, generiranje značilk ter učenje in testiranje besedilnih in zvočnih modelov ter meta modela z metodo zlaganja.
Klasifikacija sovražnega govora v slovenskem in angleškem jeziku (Nik Pirnat)
Hate speech classification for Slovene and English language
S porastom sovražnega govora na družbenih omrežjih je nastala tudi večja potreba po nadzoru, vendar bi bil zaradi velike količine informacij ročni nadzor praktično nemogoč, tako se za določanje sovražnega govora danes po večini uporabljajo nevronske mreže. Za učenje nevronskih mrež potrebujemo veliko število označenih podatkov, vendar so javno dostopne podatkovne množice redko podrobno označene, predvsem to drži za jezike z relativno malo govorci. Za slovenski jezik obstaja malo javno dostopnih podatkovnih množic, ki bi vsebovale več bolj podrobnih oznak, zato preizkusimo kako se izkaže podatkovna množica, ki je sestavljena iz več različnih množic. Na sestavljenih množicah s posplošenimi skupnimi oznakami učimo nevronsko mrežo BERT in naše rezultate primerjamo z rezultati, ki so jih dosegli avtorji prvotnih podatkovnih množic. Ugotovimo, da so rezultati, ki jih dosežemo zadovoljivi in predlagamo izboljšave, ki bi omogočile, da bi na sestavljenih množicah dosegli enako dobre rezultate kot na množicah izdelanih za določeno nalogo.
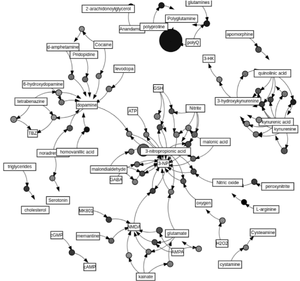
Odkrivanje biomedicinskih vzorcev za nevrodegenerativne bolezni iz biomedicinske znanstvene literature (Radoslav Atanasoski)
Mining patterns for neurodegenerative diseases from biomedical scientific literature
Dandanes obstaja ogromna količina biomedicinskega znanja, ki vsak dan hitro prihaja skozi znanstveno objavljene članke. Vendar pa je poskušati slediti temu resnično zahtevno in vzame preveč časa. Se več, pri iskanju relevantnih dokumentov z zahtevanimi podatki. Da bi zdravstvenim delavcem pomagali ostati na tekočem in najti članke, povezane z njihovimi temami iskanja, v tej diplomski nalogi ustvarimo cevovod za pridobivanje informacij (IR), pri čemer najprej navedemo, s katerimi nevrodegenerativnimi boleznimi so članki povezani, in zagotovimo tudi analizo, ki pokaže, najpogostejših vzorcev, ki so raziskani in objavljeni. Za modeliranje smo raziskali več najsodobnejših modelov učenja za predstavitev besedila, kot so BERT, RoBERTa in BioBERT. Po natančnem prilagajanju vsakega modela je bil kot model za cevovod IR izbran BioBERT, ki zagotavlja izjemno zmogljivost s 94% navzkrižno validacijo CA. Prav tako primerjamo naš najsodobnejši model z bolj tradicionalnim in pogosto uporabljenim modelom Random Forest. Poleg tega so bili za analizo pogostih vzorcev uporabljeni izvlečki vpletenih bolezni opombe in koncepti kemičnih in genetskih spojin so bili ekstrahirani z uporabo modela prepoznavanja poimenovanih entitet (NER). Po tem so bile vse entitete normalizirane z uporabo povezovanja imenovanih entitet (NEL). Na ekstrahiranih entitetah je bilo uporabljeno rudarjenje asociacijskih pravil, da bi našli najpogosteje raziskane vzorce za vsako bolezen, ki so nadalje prikazani z uporabo več tehnik vizualizacije. Ti rezultati bodo zdravstvenim delavcem pomagali pri navajanju najnovejših informacij, po drugi strani pa bodo pokazali tudi na manjkajoče vrzeli, ki za določeno bolezen niso dobro raziskane. Podatki, vključeni v to študijo, so bili pridobljeni iz javno dostopne zbirke podatkov PubMed.
Ključne besede
podatkovno rudarjenje, učenje tekstovnih predstavitev, učenje asociacijskih pravil
data mining, text representation learning, association rule mining
Komentar
Delo je bilo narejeno v somentorstvu z doc. dr. Tometom Eftimovim.
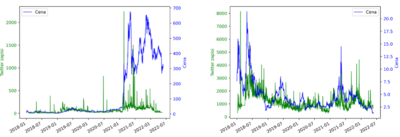
Analiza vpliva omemb kriptovalut na njihovo ceno (Tilen Miklavič)
Analysis of the impact of cryptocurrency mentions on their price
V okviru te naloge, sem raziskal, ali javni sentiment na družbenem omrežju Twitter vpliva na gibanje trga kriptovalut. Ta podatek bi lahko navdušenci izkoristili pri svojih analizah. Zbral in analiziral bom podatke za več kriptovalut in jih razvrstil v seznam po odvisnosti od javnega sentimenta. To mi bo pomagalo pri izdelavi napovednega modela, ki bo podajal obvestila o abnormalnih dogodkih na socialnih omrežjih. Uspešen rezultat naloge bo napovedni model, ki bo pravilno in časovno natančno klasificiral dogajanje na družbenem omrežju. V sodelovanju s spletno aplikacijo bi lahko tako uporabnika v realnem času o teh dogodkih obveščal.
GeoTools: spletne storitve za izvajanje prostorskih analiz (Sanil Safić)
GeoTools: Web services for performing spatial analysis
Na spletu so dostopne mnoge storitve, ki omogočajo napredne prostorske analize, a so le te pomankljive, omejene ali pa se ponujajo v obliki programske opreme. S spletno storitvijo GeoTools prostorske analize iz različnih virov povežemo v eno samostojno celoto. GeoTools vsebuje module iz knjižnice GeoPandas, QGIS in PostGIS. Storitev ima implementiran tudi cevovod prostorskih analiz, kar pomeni, da lahko zaporedoma opravi več želenih analiz. GeoTools uporabniku, predvsem programerju, olajša implementacijo prostorskih analiz v projektih. Za lažjo uporabo smo razvili NPM knjižnico, ki se povezuje na storitev in vsakomur omogoči enostaven dostop do njenih funkcionalnosti. NPM knjižnica vsebuje tudi enostaven grafični vmesnik, ki s pomočjo knjižnice OpenLayers omogoči uporabniku, da svoje vhodne in izhodne podatke tudi prikaže na spletni karti.
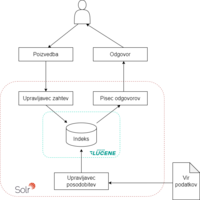
Analiza in primerjava sistemov za informacijsko poizvedovanje (Mark Redelonghi)
Analysis and comparison of information retrieval systems
V diplomskem delu se je analiziralo in primerjalo manjšo množico sistemov za informacijsko poizvedovanje. Raziskava se je osredotočila na iskanje po besedilu, kjer se uporabi procesiranje naravnega jezika. Izbrani sistemi so bili primerjani glede na način delovanja, indeksiranja, poizvedovanja ter časovne in prostorske lastnosti. Za primerjavo se je pridobilo korpuse besedil in definiralo poizvedbe s katerimi se je primerjalo izbrane sisteme. V zaključku so podane prednosti in slabosti sistemov skupaj s primeri uporabe.
Ključne besede
računalnik, procesiranje naravnega jezika, solr, milvus, podatki, iskanje
computer, natural language processing, solr, milvus, data, search
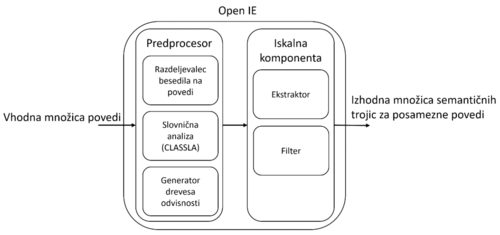
Odprta ekstrakcija informacij za slovenski jezik (Miha Bogataj)
Open information extraction for Slovenian language
Odprta ekstrakcija informacij je proces procesiranja naravnega jezika, ki iz posameznih povedi izvleče možne odvisnosti. Odvisnosti so sestavljene iz semantične trojice, kjer prvi člen predstavlja subjekt o katerem poizvedujemo, relacije, ki opiše, kako se prvi člen navezuje na tretjega, in objekt. Sistem odprte ekstrakcije informacij za slovenščino temelji na metodi na podlagi pravil. Sistem je sestavljen iz predprocesorja in ekstraktorja. Vloga predprocesorja je obdelava vhodnega besedila s pomočjo sistema CLASSLA, ki slovnično analizira poved, lematizacija in izgradnja semantičnega drevesa. Vloga ekstraktorja je, da z uporabo pravil poišče relacije v povedi. Ta pravila so bolj kompleksna kot v angleščini, ker je v slovenščini besedni red bolj prost. Slovenščina pozna tudi več sklanjatev, ki omogočajo bolj točno določitev subjekta in objekta. Med najdenimi ekstrakcijami je možno iskanje na dva načina: iskanje povedi in dopolnjevanje parametrov. Iskanje povedi zahteva izpolnjene vse parametre semantične trojice in vrne seznam povedi, ki ustrezajo iskani semantični trojici. Dopolnjevanje parametrov zahteva dva izpolnjena parametra, od katerih je relacija obvezna. Ta način vrne seznam možnih vrednosti za manjkajoč parameter.
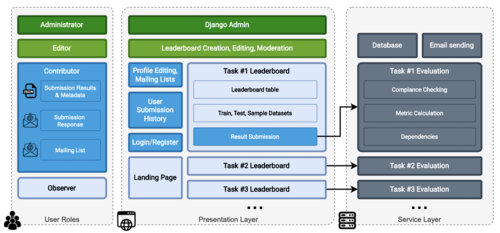
SloBench: Slovenski vrednotnik metod za obdelavo naravnega jezika (Frenk Dragar)
SloBench: Slovenian Natural Language Processing Benchmark
Z nedavno priljubljenostjo modelov obdelave naravnega jezika, ki temeljijo na arhitekturi transformer, in njihove najsodobnejše zmogljivosti pri številnih nalogah NLP, je vse večja potreba po objektivnem ocenjevanju teh orodij in omogočanju njihove primerjave. Obstajajo številni nabori podatkov in meril za NLP naloge, ki pa večinoma temeljijo na angleškem jeziku. V diplomski nalogi kandidat opiše razvoj prve slovenske platforme za avtomatsko primerjavo NLP modelov - SloBench, skupaj z njenim razširljivim in od sistemske arhitekture neodvisnim ogrodjem za evalvacijo sistemov. Nato kritično oceni projekt, ga primerja z obstoječimi merili uspešnosti NLP in poda nekaj idej za prihodnje razširitve platforme.
Evalvacija nalog procesiranja naravnega jezika (NLP) je bistven del raziskav in napredka na tem področju. Zagotavlja objektiven standard za uspešnost in primerjavo sistemov pri določeni nalogi. Podamo pregled nedavnih javnih lestvic za najboljše sisteme in trendov njihovega ocenjevanja s poudarkom na avtomatskem vrednotenju sistemov. Nato predlagamo, implementiramo in dokumentiramo splošno, razširljivo in od sistemske arhitekture neodvisno ogrodje za evalvacijo sistemov, skupaj s prvo spletno platformo za avtomatsko vrednotenje NLP nalog v slovenščini z javnimi lestvicami, ki prikazujejo rezultate objavljenih sistemov.
Ključne besede
procesiranje naravnega jezika, vrednotenje, lestvica najboljših, strojno učenje, spletna platforma
natural language processing, benchmarking, leaderboard, machine learning, web platform
Obdelava velikih količin podatkov v skoraj realnem času (Anže Habjan)
Near real-time processing of large amounts of data
V času, ko količina generiranih podatkov na spletu narašča tako hitro kot še nikoli, je toliko bolj pomembno, da je obdelava le teh kar se da hitra. Opišemo implementacijo celostnega sistema, ki bo specializiran za obdelavo pretočnih podatkov v skoraj realnem času, in bo vključeval po eno orodje za vsak del: pridobivanje, obdelava, shranjevanje in vizualizacija. Posamezna orodja so utemeljeno izbrana na podlagi našega realnega primera uporabe sistema, ki je obdelava čivkov (tweet), ki nastanejo na omrežju Twitter v času nogometne tekme. Na primeru uporabe tudi prikažemo analize in vizualizacije, ki jih omogoča implementiran sistem. Zaključimo s prikazom nekaj metrik našega sistema v času obdelave.
Ključne besede
veliki podatki, obdelava, skoraj realni čas, Twitter, nogomet
big data, processing, near real-time, Twitter, football
Primerjava in analiza statičnih generatorjev spletnih strani (Luka Toni)
Comparison and analysis of static Web site generators
Na spletu obstaja veliko načinov, kako ustvariti spletno stran in veliko različnih sistemov za upravljanje z vsebino, ki jih lahko uporabimo. Na voljo imamo različne spletne generatorje strani, kjer z malo tehničnega znanja lahko enostavno in hitro naredimo sodobno spletno stran.
Generator statičnih strani je kompromis med ročno napisano kodo in polnim sistemom za upravljanje z vsebino, ki uporablja prednosti obeh. Primerjali smo 3 različne generatorje: Jekyll, Hugo in Gatsby. Na vseh treh generatorjih smo definirali ključne gradnike, ki jih ima povprečna spletna stran in jih implementirali z vsakim sistemom posebej ter nato primerjali med seboj. Poiskali smo prednosti in slabosti vseh treh generatorjev ter se posvetili temu, kako izdelati spletni dnevnik.
Implementacija storitve za deljenje in spremljanje lokacije (Matej Baša)
Implementation of location tracking service
Lokacijske storitve so v mobilnih napravah postale zelo pomembne. Veliko aplikacij spremlja lokacijo uporabnika ter na podlagi te pošilja promocijska sporočila, prikaže ustanove v bližnji okolici, napove temperaturo na trenutni lokaciji ipd.
Diplomsko delo opisuje in analizira postopek implementacije in razvoja lokacijsko zavedne storitve na platformi Android s pomočjo programskega jezika Java. V delu je predstavljen celoten razvoj aplikacije, vse uporabljene plat- forme, orodja in knjižnice ter tehnologije lokacijske zavednosti. Pozornost je namenjena varnosti podatkov in preprosti implementaciji lokacijskih storitev.
Samodejno prepoznavanje vsebinskih blokov znotraj spletišč (Mitja Brezovnik)
Automatic identification of content blocks from Web sites
Informacije so dandanes enostavno dostopne, informiranost pa ključnega pomena. S to mislijo smo se lotili izdelave rešitve, ki bo omogočala luščenje vsebine člankov iz slovenskih novičarskih portalov. Glavni problem s katerim se pri tovrstnih rešitvah soočimo je ločitev vsebine od nepotrebnih informacij, kot so oglasi, komentarji in ostali postavitveni elementi spletnih strani. Za rešitev tega problema smo ubrali pristop, ki temelji na značilnostih plitkih besedil. Na njegovi osnovi smo zasnovali jezikovni model, ki smo ga zgradili s pomočjo slovenskega korpusa 10000 slovenskih člankov iz 5 različnih novičarskih portalov. Končni izdelek predstavlja ekstraktor, ki omogoča pridobitev vsebine slovenskih člankov in jih predstavi v strukturirani obliki.
Podpora za implementacijo večjezičnosti za spletne aplikacije (Tomaž Nemanič)
Implementation of multilingual support for Web applications
V diplomski nalogi je celovito proučena aktualna podpora za implementacijo večjezičnosti na spletnih straneh. Prikazanih je več načinov implementacije za večjezičnost v spletišču "Mes. Ključnega pomena je točnost prevajanih podatkov aplikacije, zato se na dani platformi uresničuje prevajanje orodnih vrstic oziroma splošnih podatkov na čelnem delu aplikacije, prevajanje specifičnih pojmov pa z uporabo relacijske podatkovne baze na zalednem delu aplikacije. Poimenovanja proizvodov, njihovih lastnosti in drugih storitev so specifični strokovni pojmi, ki jih je potrebno stalno dodajati, spreminjati ali celo izbrisati iz evidence v določenem podjetju, zato se implementacija vrši na zalednem delu. Internacionalizacija in lokalizacija zagotovita prevajanje v jezik okolja, v katerem se uporabnik nahaja. Sodobna aplikacija upošteva tudi najboljše uporabniške izkušnje.
Optimizacija priprave in pregled oglaševanja na platformi Twitter (Domen Tominec)
Optimization of creation and preview of advertising on Twitter platform
V dobi, ko postaja oglaševanje na družbenih omrežjih vedno donosnejši posel, se večina podjetij z oglaševalskimi rešitvami srečuje s težavo, kako razviti nove funkcionalnosti, s katerimi si bodo zagotovili konkurenčno prednost. V diplomski nalogi je predstavljena ideja ter razvoj funkcionalnosti, ki uporabnikom Httpoolove platforme \sn{Wise.Blue} omogoči hitrejšo in enostavnejšo pripravo twitterjevih oglasov. Predstavljeno je področje oglaševanja na družbenih omrežjih, glavni kanali ter največja slovenska podjetja na tem področju ter njihove rešitve. Podrobno so razloženi problem, postopek reševanja, uporabljena orodja in tehnologije, končni rezultati ter še odprta vprašanja.
Celostno upravljanje s prehodi IoT za namene oddaljenega spremljanja pacientov (Jernej Cvek)
End-to-end IoT gateway management for remote patient monitoring
Internet stvari odpira neštete možnosti za izboljšanje življenja ljudi v različnih aplikacijskih domenah, tudi na področju zdravstvene oskrbe. V rešitvah za oddaljeno spremljanje pacientov so prehodi vezni člen med raznovrstnimi zdravstvenimi merilnimi napravami in platformo za omogočanje zdravstvenih aplikacij. Za učinkovito in pravilno delovanje prehodov je potrebno na platformi zagotoviti ustrezno podporo za vse postopke in dogodke, ki se zgodijo v življenjskem ciklu prehoda. Ključni prispevki tega diplomskega dela so predlagana referenčna arhitektura IoT, definicija faz življenjskega cikla prehoda ter opis postopkov, potrebnih za celostno upravljanje prehodov v rešitvah oddaljenega spremljanja pacientov.
Vrednotenje in združevanje novic iz slovenskih spletnih medijev (Žan Horvat)
Ranking and aggregation of Slovenian online news
Na spletu obstaja mnogo različnih spletnih strani z novicami, ki pogosto vsebujejo podobne novice. Kakovost novic se med različnimi viri močno razlikuje. Prav tako obstaja kar nekaj spletnih aplikacij, ki podobne novice združujejo. Pogosto uporabniku ponudijo najbolj svežo novico, čeprav ta ni nujno najbolj informativna. Namen diplomske naloge je nadgradnja osnovnega agregatorja novic. Diplomska naloga zajema analizo spletnih mest z novicami in razvoj spletne aplikacije, ki zbira novice. Te združi s podobnimi in jih razvrsti tako, da izpostavi boljše na podlagi algoritmičnega vrednotenja. Aplikacija je sestavljena iz treh komponent, ki so izdelane v programskih jezikih JavaScript, TypeScript in Python.
Prva komponenta zbira vsebino in ponuja dostop do te preko REST API-ja. Implementirana je s pomočjo Node.js, Express in MongoDB. Druga komponenta vrednoti in združuje besedila s pomočjo strojnega učenja in je implementirana v programskem jeziku Python. Tretja komponenta je implementirana s pomočjo ogrodja Angular, za prikaz rezultatov analize zbranih besedil.
Avtomatsko pridobivanje in prikaz podatkov o slovenskih zdravnikih (Jan Šturm)
Automatic acquisition and visualization of Slovenian doctors' data
V okviru diplomske naloge smo implementirali sistem za pridobitev in prikaz obremenitev slovenskih zdravnikov. Sistem smo poimenovali FrejDohtarji, saj uporabnikom omogoča lažji pregled nad zasedenostjo osebnih zdravnikov, zobozdravnikov in ginekologov. Uporabnik lahko na prvi strani filtrira zdravnike glede na tip izvajalca in območno enoto. Pri vsakem zdravniku se prikaže barvna oznaka, ki ponazarja, ali je še dolžan sprejemati nove paciente. Kriteriji so določeni s strani Zavoda za zdravstveno zavarovanje Slovenije, hkrati pa so relativno komplicirani, zaradi česar bodo barvne oznake poenostavile pregled dejanske obremenitve zdravnikov. Sistem podatke pridobiva iz različnih virov. Podatke o zdravnikih in njihovih obremenitvah pridobijo iz excelovih datotek, ki se nahajajo na spletni strani ZZZS. Dodatne informacije o delovnih časih in kontaktih pa se avtomatsko pridobijo s spletnih strani, kjer so objavljeni. Z uporabo aplikacije FrejDohtarji bo tako izbira zdravnika lažja in hitrejša, hkrati pa bodo na enem mestu zbrani še vsi dodatni podatki o zdravniku.