Software and datasets
Some useful research results we have been working on. Here I do not list Github repositories that are not packaged as a standalone software component.
Software
CLASSLA connector for Solr
Solr is a search platform that provides an indexing engine for documents. It uses Lucene, a natural language processing framework, which also provides sofisticated tokenization and stemming. CLASSLA (fork of Stanza) is a python library that can process Slovenian, Croatian, Serbian, Macedonian and Bulgarian using PyTorch neural networks.
Aljaž Eržen has implemented a plugin for Solr with support for Slovenian. The plugin is implemented as a gRPC client that communicates with CLASSLA instance.
Lucene analyzer calls a gRPC service, where CLASSLA allows for text tokenization, stemming and lematization.
The tool is avalable in a Github repository.
SloBENCH - Slovenian NLP Benchmark
Within a Clarin.si 2021 project we implemented an automated Slovenian NLP Benchmark. It allows for adding various leaderboards and automated benchmarking.

The evaluation scripts are publicly available in a Github repository.
nutIE
NutIE (codename) will be an end-to-end information extraction toolkit. It will consist of a self-contained runnable web application (GUI) and Scala library for programmatic access.
The tool currently supports the data import and visualization, model training and evaluation for the coreference resolution task.
The project currently consists of two separate projects:
- Web-based managements part: nutIE Web
- Backend with REST API and programmatic Scala library to use in third-party projects: nutIE Core
-
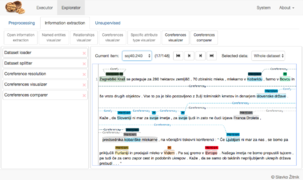 nutIE: End-to-end information extraction tool
nutIE: End-to-end information extraction tool -
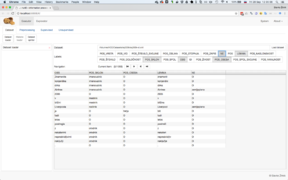 nutIE: Arbitrary data browser
nutIE: Arbitrary data browser -
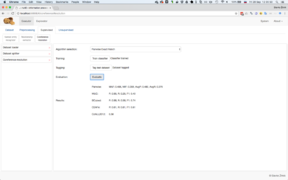 nutIE: Model training
nutIE: Model training -
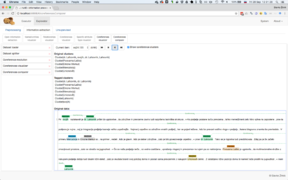 nutIE: Coreference resolution visualization
nutIE: Coreference resolution visualization




Lemmagen4J
I have rewritten Lemmagen v3.0 (http://lemmatise.ijs.si/) from C# to Java code. The eclipse project is available here: Lemmagen4J.zip.
See Train and Test classes and other code for documentation purposes. For building Slovene model, you can use Slovene part from MULTEXT-EAST dataset.
You can read more about Lemmagen in the author's paper: Lemmagen Paper, 2010.
Merging and matching framework
Framework for matching and merging using semantics. It implements attribute resolution, collective entity resolution and redundancy elimination techniques with various metrics and approaches. Download the project along with the datasets here: Data Merging framework, october 2011.
Read more: Žitnik S., Šubelj L., Lavbič D., Vasilecas O., Bajec M. (2013). General Context-Aware Data Matching and Merging Framework in Informatica, vol. 24, num. 1, pp. 119-152. Article
Datasets
Slovene corpus for aspect-based sentiment analysis - SentiCoref 1.0
SentiCoref 1.0 corpus consists of 837 documents selected from SentiNews 1.0 corpus (http://hdl.handle.net/11356/1110). The documents were selected based on the number of automatically detected named entities (using Polyglot, https://polyglot.readthedocs.io/) which contained between 50 and 73 named entities.
The corpus is provides an initial dataset for aspect-based sentiment analysis. The annotations consist of named entities (persons, organizations and locations), coreferences to the named entities, and 5-level sentiment annotation for each entity (coreference chain). Together there are 31,419 manually tagged named entities - 15,285 organizations, 8,606 persons and 7,528 locations. The dataset contains 14,572 coreference chains. Sentiment distribution for entities is as follows - 30 Very negative, 1801 Negative, 10869 Neutral, 1705 Positive and 24 Very positive.
Each document was annotated by two linguist students. In the preparation of the dataset, 8 students participated: Rednak Pia, Roblek Rebeka, Jelovšek Tjaša, Agović Haris, Vaupotič Jana, Grego Annamaria, Vidic Zala, Žvanut Kaja. The final curation was done by Neli Blagus and Slavko Žitnik.
The data is in WebAnno TSV 3 format (similar to CoNLL format) which is compatible with the WebAnno tool (https://webanno.github.io/webanno/).
Corpus is publicly available at http://hdl.handle.net/11356/1285.
Slovene coreference resolution corpus coref149
This corpus contains a subset of the ssj500k v1.4 corpus, http://hdl.handle.net/11356/1052. Each of 149 documents contains a paragraph from ssj500k that contains at least 100 words and at least 6 named entities. The data is in TCF format, exported from the WebAnno tool, https://webanno.github.io/webanno/.
The annotated entities are of type person, organization or location. Mentions are annotated as coreference chains without additional classifications of different coreference types. Annotations also include implicit mentions that are specific for the Slovene language - in this case, a verb is tagged. The corpus consists of 1277 entities, 2329 mentions, 831 singleton entities, 40 appositions and 215 overlapping mentions. We also annotated overlapping mentions of the same entity - for example in text [strokovnega direktorja KC [Zorana Arneža]] we annotate two overlapping mentions that refer to the same entity. There are 97 such mentions in the corpus.
In the public source code repository https://bitbucket.org/szitnik/nutie-core class TEIP5Importer contains an additional function to read the dataset and merge it together with the ssj500k dataset.
Corpus is publicly available at http://hdl.handle.net/11356/1182.
Slavko Public Facebook
The network contains public data, crawled from March to May 2012. It contains 51.394.379 nodes with 136.048.906 edges (4.431.920 double edges). There are 373.476 checked nodes and 50.687.612 unchecked nodes (situation in tables at the end). Non-anonymized data contains real Facebook ID, Name and Username of every user in the network. For more, see license file next to the network: Anonymized Facebook network. Some basic analysis is available as homework 3 to Big Networks class, taught by prof. dr. Vladimir Batagelj.
Slovene news
Slovene news v1 is tagged according to standard BIO scheme. The corpus contains annotated entities (B-PER (131), I-PER (74), B-ORG(162), I-ORG(158), O(5508)), relation descriptors (B-REL(32), I-REL(24), O(5977)) and coreference descriptors (B-COREF(274), I-COREF(249), 0(5510)). The dataset was lemmatized and POS-tagged using slovene POS tagger. In the dataset, there are 285 sentences with 6034 tokens.
Slovene news v2 is upgraded v1, which contains CoNLL2012-like tagged coreference tags and documents separated by ###.
The material can be used for research purposes only.