(6 intermediate revisions by the same user not shown)
Line 1:
Line 1:
__NOTOC__
This Web page contains on-going and finished master theses. Thanks to all the candidates below that did (or are doing) great work!
This Web page contains on-going and finished master theses. Thanks to all the candidates below that did (or are doing) great work!
If you are looking to prepare a master thesis under my supervision, please check [[Theses topics|available theses topics or propose your own idea]].
If you are looking to prepare a master thesis under my supervision, please check [[Theses topics|available theses topics or propose your own idea]].
== Teme v izdelavi ==
== 2024 ==
{{Thesis
|Naslov=S poizvedovanjem obogateno generiranje besedil z domensko specifičnim doučevanjem velikih jezikovnih modelov
|NaslovEng=Retrieval-augmented text generation with domain-specific large language models fine-tuning
|Avtor=Marko Ivanovski
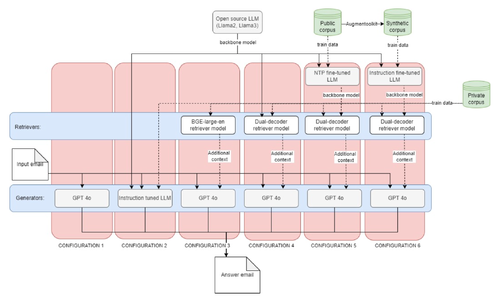
|Opis=[[File:Screenshot 2025-02-28 at 14.16.28.png|500px|right]]Razvoj avtomatiziranega sistema za odgovarjanje na vprašanja, ki poenostavi obdelavo e-pošte za podporo strankam, je učinkovita rešitev za zmanjšanje časa in truda pri ročnem odgovarjanju. Trenutno agenti za podporo strankam na e-pošto odgovarjajo ročno, kar je zamudno in delovno intenzivno. Preizkusili smo več konfiguracij za vzpostavitev sistema, ki lahko samodejno odgovarja na ta e-poštna sporočila. Uporabljene podatke je zagotovilo podjetje Zebra BI, sestavljali pa so jih strukturiran korpus elektronskih sporočil podpore in nestrukturiran korpus, pridobljen iz dokumentacije izdelka. Primerjali smo dva glavna pristopa. Prvi je obsegal doučevanje velikega jezikovnega modela za neposredno odgovarjanje na e-pošto. Ta pristop je vseboval samo generator. Drugi je uporabljal arhitekturo RAG (angl. Retrieval-Augmented Generation), ki je vsebovala tako poizvedovalnik (angl. retriever) kot generator. Poizvedovalnik je poiskal podobne e-poštne odgovore in jih dodal kot kontekst za vnaprej naučen model LLM, ki je nato odgovarjal na vprašanje z uporabo prejšnjih podobnih e-pošt. V ta namen smo implementirali dvojno-dekodirni poizvedovalni model, pri čemer smo uporabili tehniko učenja LoRA in kvantizacijo. Dvojno-dekodirni poizvedovalni model je ustvaril vgradnje (angl. embeddings) tako za vprašanja kot odgovore z uporabo ločenih dekodirnikov in jih razvrstil glede na kosinusno podobnost. Razvili smo šest različnih konfiguracij sistema za odgovarjanje na vprašanja. Nekatere konfiguracije so uporabljale tako komponento poizvedovalnika kot generatorja, druge pa so imele samo generator. Najbolje se je izkazala konfiguracija s prilagojenim dvojno-dekodirnim poizvedovalnim modelom, ki je izboljšala sposobnost sistema za iskanje relevantnih informacij iz domensko-specifičnega e-poštnega korpusa. To je tudi pokazalo, da je učenje poizvedovalnika in uporaba arhitekture RAG učinkovitejša rešitev od doučevanja modela LLM, kadar je količina podatkov majhna in nizke kakovosti. Najbolj optimalen poizvedovalnik, zgrajen na arhitekturi Llama-2-7B z uporabo LoRA in 4-bitne kvantizacije, je dosegel natančnost 0.53 pri Accuracy@100 in 0.032 pri MRR@100. V primerjavi s tem je najsodobnejši model poizvedovalnika BGE-large-en dosegel 0.282 pri Accuracy@100 in 0.009 pri MRR@100 v isti domeni. V kombinaciji z GPT-4o kot generatorjem je v našem ročnem ocenjevanju poizvedovalnik z dvojno-dekodirnim modelom prejel oceno 1282 ELO, medtem ko je poizvedovalnik BGE-large-en z istim generatorjem dosegel oceno 1256, doučeni LLM model pa oceno 1071. Eksperimenti so pokazali, da konfiguracija z dvojno-dekodirnim poizvedovalnim modelom zagotavlja najbolj natančne in kontekstualno ustrezne odgovore ter tako presegla najsodobnejšo konfiguracijo. Prav tako so pokazali, da je možno LLM modele z dekodirnikom uporabiti za gradnjo poizvedovalnika z relativno majhno količino podatkov. Končni sistem, integriran v Chrome razširitev, je močno vplival na delovne procese podpore v Zebra BI z avtomatizacijo velikega dela odgovarjanja. S tem se je ne le zmanjšal čas odgovarjanja, ampak se je izboljšala tudi natančnost in doslednost odgovorov za stranke. Razširitev zdaj ekipa podpore v Zebra BI uporablja pol-avtomatsko, kar omogoča agentom, da se osredotočijo na bolj zahtevna vprašanja.
|KljucneBesede=Ustvarjanje besedil, odgovarjanje na vprašanja, iskanje, kodirnik, dekodirnik, transformatorji, iskanje nestrukturiranih podatkov, natančna nastavitev, modeli vgrajevanja, kvantizacija
|Viri=[{{filepath:63180365-Marko Ivanovski-dispozicija.pdf}} Dispozicija] [{{filepath:63180365-Marko Ivanovski-S poizvedovanjem obogateno generiranje besedil z domensko specifičnim doučevanjem velikih jezikovnih modeloveli-2.pdf}} Magistrsko delo]
}}
{{Thesis
|Naslov=Avtomatizacija vdornega testiranja spletnih strani
|NaslovEng=Web site penetration testing automation
|Avtor=Gregor Kerševan
|Opis=[[File:Screenshot 2025-02-28 at 14.12.49.png|500px|left]]V tem delu se ukvarjamo s problemom avtomatiziranega iskanja ranljivosti spletnih aplikacij v okviru procesov DevSecOps in cevovodov CI/CD. Uvedba varnostnih testov v avtomatiziran proces predstavlja izziv, saj je nekatere ranljivosti težko avtomatizirano iskati ali zahtevajo ročne posege, kot so ročni vdorni testi. Naš pristop vključuje implementacijo agenta, ki avtomatsko izvaja varnostne teste in analizira rezultate v grafičnih prikazih. Rešitev smo integrirali v cevovod DevOps ter testirali nad odprtokodnimi aplikacijami. Končni prispevek naloge omogoča boljši nadzor nad varnostjo spletnih aplikacij ter poenostavi proces iskanja ranljivosti za varnostne inženirje.
|KljucneBesede=avtomatizacija, devsecops, sast
|KljucneBesedeEng=automation, devsecops, sast
|Komentar=Somentor pri delu je bil viš. pred. dr. David Jelenc.
|Naslov=Izbiranje sistema za upravljanje z grafnimi podatkovnimi bazami
|NaslovEng=Selecting a graph database management system
|Avtor=Nino Brezac
|Opis=Grafne podatkovne baze so se izkazale kot učinkovito orodje za upravljanje z zelo povezanimi podatki, saj v posebnih primerih uporabe, kot so priporočilni sistemi, družbena omrežja in odkrivanje goljufij, celo presegajo tradicionalne relacijske podatkovne baze. V tem delu so najprej predstavljeni koncepti grafnih podatkovnih baz, njihova taksonomija in posebnosti. Nato sledi celostna predstava področja grafnih podatkovnih baz, kjer so povzete ključne lastnosti reprezentativnega vzorca grafnih podatkovnih baz in je posledično zgrajen model odločitvenega drevesa za pomoč pri izbiri grafne podatkovne zbirke. Za validacijo je izbran primer uporabe analitičnih podatkovnih zbirk LPG. Validacija je vsebovala eksperimentalno analizo na standardiziranem naboru podatkov, ter je izpostavila ključne razlike med sistemi glede uporabniškega vmesnika, uporabniške izkušnje, hitrosti, porabe pomnilnika in analitičnih zmožnosti. Ta študija ponuja praktičen vpogled za skrbnike podatkovnih baz in razvijalce, ki želijo izbrati pravo rešitev grafne podatkovne zbirke za svoje specifične potrebe.
|Viri=[{{filepath:63180347-Nino Brezac-dispozicija.pdf}} Dispozicija] [{{filepath:63180347-Nino Brezac-Izbiranje sistema za upravljanje z grafnimi podatkovnimi bazami.pdf}} Magistrsko delo]
}}
{{Thesis
|Naslov=Avtomatizirana gradnja učnih korpusov s pomočjo velikih jezikovnih modelov
|NaslovEng=Automatized construction of learning corpuses with the help of large language models
|Avtor=Gal Petkovšek
|Opis=[[File:Screenshot 2025-02-28 at 14.07.15.png|500px|right]]Zbiranje in označevanje podatkov je drago in zamudno. V tem delu predstavljamo ogrodje, ki izkorišča moč velikih jezikovnih modelov za umetno tvorjenje sintetičnih podatkov. Testirali smo ga na treh nalogah uvrščanja besedil in z njegovo uporabo izboljšali izhodiščen rezultate. Predstavili smo več metod ocenjevanja kvalitete umetnih množic ter predstavili, kako ugotovitve uporabimo za razvoj novih pristopov tvorjenja umetnih primerkov. Razvitih in testiranih je bilo več tehnik umetnega tvorjenja, od katerih izstopa dodajanje pogostih besed v ukazni poziv, kar bistveno izboljša rezultate v primeru, ko imamo na voljo tako majhno množico označenih, kot tudi veliko množico neoznačenih primerkov. Najboljše rezultate smo dosegli z združevanjem umetno tvorjenih podatkov in LLM-označenih primerkov iz velike množice neoznačenih primerkov. Glavni prispevki naloge vključujejo implementacijo ogrodja in razvite strategije tvorjenja, ki smo jih vrednotili z različnimi metrikami na več scenarijih.
|KljucneBesedeEng=large language models, synthetic data, natural language porcessing, text classification, datasets
|Komentar=
|Viri=[{{filepath:63170020-Gal Petkovšek-dispozicija.pdf}} Dispozicija] [{{filepath:63170020-Gal Petkovšek-Avtomatizirana gradnja učnih korpusov s pomočjo velikih jezikovnih modelov.pdf}} Magistrsko delo]
}}
{{Thesis
|Naslov=Avtomatska ekstrakcija podatkov iz računov
|NaslovEng=Automatic invoice data extraction
|Avtor=Gregor Ažbe
|Opis=[[File:Screenshot 2025-02-28 at 14.04.29.png|300px|left]]V tem magistrskem delu se osredotočamo na problem prepoznavanja podatkov z računov, ki so ključni administrativni dokumenti v poslovanju podjetij. Podjetja potrebujejo podatke računov v digitalni obliki, da jih lahko računalniško obdelujejo. Kljub naraščajoči uporabi elektronskih računov so ti večinoma v formatu PDF in ne vsebujejo strukturiranih metapodatkov, kar otežuje avtomatizirano ekstrakcijo podatkov. Ročno prepisovanje podatkov je zamudno in nagnjeno k napakam, zato je avtomatizacija tega procesa izjemnega pomena.
:V delu smo implementirali, opisali in primerjali uspešnost treh različnih pristopov za avtomatsko ekstrakcijo podatkov z računov. Prvi pristop temelji na klasičnih metodah strojnega učenja, kjer smo preizkusili več modelov, vključno z odločitvenimi drevesi, naključnimi gozdovi, metodami podpornih vektorjev in drugimi. Drugi pristop temelji na grafovskih nevronskih mrežah (GNN), tretji pa na pristopu s predlogami, ki ne uporablja strojnega učenja. Značilke za strojno učenje so vključevale pozicijske podatke, kot so položaj, velikost očrtanega pravokotnika in številka strani, ter besedilne značilke, kot so prisotnost določenih besed v okolici in število določenih znakov v besedi.
:Naš pristop s klasičnim strojnim učenjem je dosegel najboljše rezultate, saj smo z uporabo ekstremno naključnih dreves dosegli F1 = 0,89. Pristop z GNN je dosegel F_1 = 0,87, medtem ko je pristop s predlogami dosegel F1 = 0,70.
:Ekstremno naključna drevesa so se izkazala za najprimernejši pristop, saj je poleg najvišje uspešnosti njihova prednost tudi v nižji računski zahtevnosti in v tem, da v primerjavi z GNN za učenje potrebujejo manj učnih primerov.
:V primeru, da bi se pojavila potreba po dodajanju novih polj, bi morali pri pristopih s strojnim učenjem pridobiti veliko računov z novim poljem za učenje in ustrezno popraviti modele. Pri pristopu s predlogami pa bi zadoščal samo en račun z novim poljem za vsak tip računa, s katerim bi popravili ustrezno predlogo. V nadaljnjem delu bi lahko raziskali dodatne pristope, ki bi omogočali hitro učenje na podlagi le nekaj računov ali pa različne pristope z ANN, saj ti običajno zagotavljajo višjo uspešnost.
|Komentar=Mentor dela je izr. prof. dr. Lovro Šubelj.
|Viri=[{{filepath:63150040-Gregor Ažbe-dispozicija.pdf}} Dispozicija] [{{filepath:63150040-Gregor Ažbe-Avtomatska ekstrakcija podatkov iz računov.pdf}} Magistrsko delo]
}}
== 2023 ==
{{Thesis
{{Thesis
|Naslov=Ekstrakcija informacij iz zdravstvenih dokumentov
|Naslov=Profiliranje uporabnikov in dinamično priporočanje produktov z vektorskimi bazami
|NaslovEng=Extracting information from medical documents
|NaslovEng=User profiling and dynamic product recommendation with vector databases
|Avtor=Matic Bernik
|Avtor=Denis Derenda Cizel
|Opis=
|Opis=[[File:Screenshot 2025-02-28 at 13.58.38.png|300px|right]]Količina podatkov se iz dneva v dan povečuje. Z namenom filtriranja velikega toka podatkov so bili razviti različni priporočilni sistemi, ki izvajajo preslikavo med uporabniki in predmeti priporočanja z namenom čim hitrejše interakcije med njimi. V magistrskem delu se posvetimo priporočilnim sistemom na podlagi sodelovanja in delovanje preverimo na podatkih o telekomunikacijskih storitvah uporabnikov. Priporočanje ovrednotimo z različnimi merami uspešnosti. Sodelovalno priporočanje z namenom izboljšanja priporočanja nadgradimo v različne hibridne pristope. Hibridni pristop z dodatkom demografskih podatkov pravilno predlaga 85 odstotkov uporabniških priporočil. Z upoštevanjem zaporedja interakcij je mogoče pravilno napovedati naslednjo uporabniško storitev v 74 odstotkih. Implementirano je bilo tudi shranjevanje vektorskih predstavitev v vektorsko bazo, ki naredi priporočilni dostop bolj dostopen za uporabo.
|KljucneBesede=
|KljucneBesede=priporočilni sistemi, profiliranje, vsebinsko osnovana metoda, metoda izbiranja s sodelovanjem, vektorska baza
|Viri=[{{filepath:63160090-Denis Derenda Cizel-dispozicija.pdf}} Dispozicija] [{{filepath:63160090-Denis Derenda Cizel-Profiliranje uporabnikov in dinamično priporočanje produktov z vektorskimi bazami.pdf}} Magistrsko delo]
}}
}}
{{Thesis
{{Thesis
|Naslov=Avtomatska prepoznava in digitalizacija obrazcev
|Naslov=Avtomatska prepoznava in digitalizacija obrazcev
|NaslovEng=Automatic recognition and digitalisation of forms
|NaslovEng=Automatic recognition and digitalisation of forms
|Avtor=Robert Tovornik
|Avtor=Robert Tovornik
|Opis=
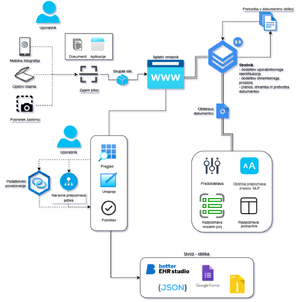
|Opis=[[File:Screenshot 2025-02-28 at 13.54.00.png|300px|right]]Celostna digitalna transformacija organizacije zahteva digitalizacijo obstoječih in novo nastajajočih podatkov. Organizacije, ki podatke zajemajo preko vnosnih obrazcev v fizični papirni obliki, kot na primer večina zdravstvenih organizacij, morajo za pospešitev digitalizacije digitalizirati tudi vnosne obrazce. Digitalizacija kompleksnih vnosnih obrazcev je nepotrebno časovno zahtevna, saj je proces mogoče avtomatizirati. V sodelovanju s podjetjem Better, ki že omogoča kreiranje digitalnih obrazcev, smo razvili programsko rešitev za avtomatsko prepoznavo in digitalizacijo obrazcev. Programska oprema, razvita za delovanje v oblaku, uporablja tehnologijo optičnega prepoznavanja znakov, polj za vnos besedila, potrditvenih in izbirnih vnosnih polj in razpredelnic ter povezovanje podatkov za natančno prepoznavanje in digitalizacijo različnih vrst obrazcev. Vključen je izbirni korak človekovega posredovanja, ki omogoča prilagoditev želenih rezultatov. Evalvacija delovanja posameznih komponent izkazuje visoko učinkovitost in natančnost delovanja primerljivo z drugimi komercialnimi ponudniki storitev, ki celostne rešitve ne ponujajo. Povratne informacije izkazujejo večjo produktivnost in časovni prihranek pri procesu digitalizacije obrazcev.
|Naslov=Samonadzorovano odkrivanje anomalij v produkcijskih dnevniških zapisih
|Naslov=Samonadzorovano odkrivanje anomalij v produkcijskih dnevniških zapisih
|NaslovEng=Self-supervised anomaly detection in production log streams
|NaslovEng=Self-supervised anomaly detection in production log streams
|Avtor=Tomaž Martinčič
|Avtor=Tomaž Martinčič
|Opis=
|Opis=[[File:Screenshot 2025-02-28 at 13.48.36.png|400px|right]]Rešitve za avtomatsko odkrivanje anomalij v sistemskih dnevniških zapisih so potrebne za učinkovito analizo in interpretacijo ogromnih količin ustvarjenih podatkov dnevnikov, odkrivanje skritih vzorcev in napovedovanje sistemskih anomalij, izboljšanje učinkovitosti delovanja, zagotavljanje varnosti sistema in zmanjšanje možnih izpadov. V zadnjem času je prišlo do razvoja na področju samodejnega odkrivanja nepravilnosti z uporabo metod strojnega učenja.
|KljucneBesede=
|KljucneBesedeEng=
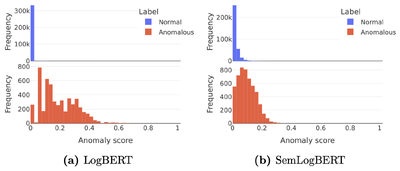
:V tem delu smo razširili na tem področju dobro znano metodo LogBERT v hierarhični transformator z vključitvijo prednaučenega jezikovnega modela za pridobitev semantičnih vložitev predlog dnevniških zapisov. S tem zagotavljamo bogatejše informacije in se izognemo težavam novih predlog, s katerimi se sooča izvirna metoda LogBERT. Predstavljamo novo metodo, imenovano SemLogBERT.
:Ugotovili smo, da rezultati, predstavljeni v večini modernih metod, močno precenjujejo njihovo učinkovitost. LogBERT in SemLogBERT smo ovrednotili v bolj realističnem scenariju, kjer smo izboljšali rezultate na nekaterih izmed standardnih primerjalnih podatkovih zbirk na tem področju.
|KljucneBesede=Obdelava naravnega jezika, odkrivanje anomalij, produkcijski dnevniški zapisi, strojno učenje, samonadzorovano strojno učenje
|KljucneBesedeEng=natural language processing, anomaly detection, production logs, machine learning, self-supervised learning
|Komentar=V sodelovanju s somentorjem iz industrije - mag. Álvaro García Faura (XLAB)
|Komentar=V sodelovanju s somentorjem iz industrije - mag. Álvaro García Faura (XLAB)
|Naslov=Avtomatizacija vdornega testiranja spletnih strani
|Naslov=Avtomatsko povzemanje pravnih besedil
|NaslovEng=Web site penetration testing automation
|NaslovEng=Automatic summarization of legal documents
|Avtor=Gregor Kerševan
|Avtor=Andrej Miščič
|Opis=
|Opis=[[File:Screenshot 2025-02-28 at 13.44.34.png|400px|right]]Uporaba sodobnih pristopov obdelave naravnega jezika je ključna, da lahko pravna industrija obdeluje velike količine besedil in zagotavlja učinkovite storitve. Pravne raziskave so področje, na katerega imajo ti pristopi največji vpliv, saj pravnikom omogočajo hitrejše iskanje ustrezne zakonodaje in sodne prakse. S ciljem zagotoviti povzetke dolgih pravnih besedil v delu obravnavamo avtomatsko povzemanje slovenskih sodnih odločb.
|KljucneBesede=
|KljucneBesedeEng=
:Predlagamo GloBerto-Sum, ekstraktivni pristop, ki temelji na nedavno predstavljenih slovenskih vnaprej naučenih jezikovnih modelih. Da lahko obravnava daljše dokumente, se naš pristop zanaša na strukturo sodnih odločb. Naučen je na mehkih oznakah, kar ublaži težave, ki jih prinaša visoko razmerje med številom povedi v dokumentih in povzetkih. GloBerto-Sum dodatno združimo z abstraktivnim modelom - tako pridobljen hibridni pristop je zmožen generirati povzetke s parafriziranjem.
:Rezultati kažejo, da naši pristopi generirajo povzetke, ki so po ustreznosti na ravni ročno napisanih, a so lahko nekoliko manj koherentni in vsebujejo več redundantnih informacij. Kljub temu menimo, da z našim delom pokažemo možnost uporabe predlagane metodologije za tvorjenje povzetkov, ki pravnikom omogočajo hitrejši pregled pravnih besedil.
S poizvedovanjem obogateno generiranje besedil z domensko specifičnim doučevanjem velikih jezikovnih modelov (Marko Ivanovski)
Retrieval-augmented text generation with domain-specific large language models fine-tuning
Razvoj avtomatiziranega sistema za odgovarjanje na vprašanja, ki poenostavi obdelavo e-pošte za podporo strankam, je učinkovita rešitev za zmanjšanje časa in truda pri ročnem odgovarjanju. Trenutno agenti za podporo strankam na e-pošto odgovarjajo ročno, kar je zamudno in delovno intenzivno. Preizkusili smo več konfiguracij za vzpostavitev sistema, ki lahko samodejno odgovarja na ta e-poštna sporočila. Uporabljene podatke je zagotovilo podjetje Zebra BI, sestavljali pa so jih strukturiran korpus elektronskih sporočil podpore in nestrukturiran korpus, pridobljen iz dokumentacije izdelka. Primerjali smo dva glavna pristopa. Prvi je obsegal doučevanje velikega jezikovnega modela za neposredno odgovarjanje na e-pošto. Ta pristop je vseboval samo generator. Drugi je uporabljal arhitekturo RAG (angl. Retrieval-Augmented Generation), ki je vsebovala tako poizvedovalnik (angl. retriever) kot generator. Poizvedovalnik je poiskal podobne e-poštne odgovore in jih dodal kot kontekst za vnaprej naučen model LLM, ki je nato odgovarjal na vprašanje z uporabo prejšnjih podobnih e-pošt. V ta namen smo implementirali dvojno-dekodirni poizvedovalni model, pri čemer smo uporabili tehniko učenja LoRA in kvantizacijo. Dvojno-dekodirni poizvedovalni model je ustvaril vgradnje (angl. embeddings) tako za vprašanja kot odgovore z uporabo ločenih dekodirnikov in jih razvrstil glede na kosinusno podobnost. Razvili smo šest različnih konfiguracij sistema za odgovarjanje na vprašanja. Nekatere konfiguracije so uporabljale tako komponento poizvedovalnika kot generatorja, druge pa so imele samo generator. Najbolje se je izkazala konfiguracija s prilagojenim dvojno-dekodirnim poizvedovalnim modelom, ki je izboljšala sposobnost sistema za iskanje relevantnih informacij iz domensko-specifičnega e-poštnega korpusa. To je tudi pokazalo, da je učenje poizvedovalnika in uporaba arhitekture RAG učinkovitejša rešitev od doučevanja modela LLM, kadar je količina podatkov majhna in nizke kakovosti. Najbolj optimalen poizvedovalnik, zgrajen na arhitekturi Llama-2-7B z uporabo LoRA in 4-bitne kvantizacije, je dosegel natančnost 0.53 pri Accuracy@100 in 0.032 pri MRR@100. V primerjavi s tem je najsodobnejši model poizvedovalnika BGE-large-en dosegel 0.282 pri Accuracy@100 in 0.009 pri MRR@100 v isti domeni. V kombinaciji z GPT-4o kot generatorjem je v našem ročnem ocenjevanju poizvedovalnik z dvojno-dekodirnim modelom prejel oceno 1282 ELO, medtem ko je poizvedovalnik BGE-large-en z istim generatorjem dosegel oceno 1256, doučeni LLM model pa oceno 1071. Eksperimenti so pokazali, da konfiguracija z dvojno-dekodirnim poizvedovalnim modelom zagotavlja najbolj natančne in kontekstualno ustrezne odgovore ter tako presegla najsodobnejšo konfiguracijo. Prav tako so pokazali, da je možno LLM modele z dekodirnikom uporabiti za gradnjo poizvedovalnika z relativno majhno količino podatkov. Končni sistem, integriran v Chrome razširitev, je močno vplival na delovne procese podpore v Zebra BI z avtomatizacijo velikega dela odgovarjanja. S tem se je ne le zmanjšal čas odgovarjanja, ampak se je izboljšala tudi natančnost in doslednost odgovorov za stranke. Razširitev zdaj ekipa podpore v Zebra BI uporablja pol-avtomatsko, kar omogoča agentom, da se osredotočijo na bolj zahtevna vprašanja.
Ključne besede
Ustvarjanje besedil, odgovarjanje na vprašanja, iskanje, kodirnik, dekodirnik, transformatorji, iskanje nestrukturiranih podatkov, natančna nastavitev, modeli vgrajevanja, kvantizacija
Text generation, question answering, retrieval, encoder, decoder, transformers, unstructured data retrieval, fine-tuning, embedding models, quantization
Avtomatizacija vdornega testiranja spletnih strani (Gregor Kerševan)
Web site penetration testing automation
V tem delu se ukvarjamo s problemom avtomatiziranega iskanja ranljivosti spletnih aplikacij v okviru procesov DevSecOps in cevovodov CI/CD. Uvedba varnostnih testov v avtomatiziran proces predstavlja izziv, saj je nekatere ranljivosti težko avtomatizirano iskati ali zahtevajo ročne posege, kot so ročni vdorni testi. Naš pristop vključuje implementacijo agenta, ki avtomatsko izvaja varnostne teste in analizira rezultate v grafičnih prikazih. Rešitev smo integrirali v cevovod DevOps ter testirali nad odprtokodnimi aplikacijami. Končni prispevek naloge omogoča boljši nadzor nad varnostjo spletnih aplikacij ter poenostavi proces iskanja ranljivosti za varnostne inženirje.
Ključne besede
avtomatizacija, devsecops, sast
automation, devsecops, sast
Komentar
Somentor pri delu je bil viš. pred. dr. David Jelenc.
Izbiranje sistema za upravljanje z grafnimi podatkovnimi bazami (Nino Brezac)
Selecting a graph database management system
Grafne podatkovne baze so se izkazale kot učinkovito orodje za upravljanje z zelo povezanimi podatki, saj v posebnih primerih uporabe, kot so priporočilni sistemi, družbena omrežja in odkrivanje goljufij, celo presegajo tradicionalne relacijske podatkovne baze. V tem delu so najprej predstavljeni koncepti grafnih podatkovnih baz, njihova taksonomija in posebnosti. Nato sledi celostna predstava področja grafnih podatkovnih baz, kjer so povzete ključne lastnosti reprezentativnega vzorca grafnih podatkovnih baz in je posledično zgrajen model odločitvenega drevesa za pomoč pri izbiri grafne podatkovne zbirke. Za validacijo je izbran primer uporabe analitičnih podatkovnih zbirk LPG. Validacija je vsebovala eksperimentalno analizo na standardiziranem naboru podatkov, ter je izpostavila ključne razlike med sistemi glede uporabniškega vmesnika, uporabniške izkušnje, hitrosti, porabe pomnilnika in analitičnih zmožnosti. Ta študija ponuja praktičen vpogled za skrbnike podatkovnih baz in razvijalce, ki želijo izbrati pravo rešitev grafne podatkovne zbirke za svoje specifične potrebe.
Avtomatizirana gradnja učnih korpusov s pomočjo velikih jezikovnih modelov (Gal Petkovšek)
Automatized construction of learning corpuses with the help of large language models
Zbiranje in označevanje podatkov je drago in zamudno. V tem delu predstavljamo ogrodje, ki izkorišča moč velikih jezikovnih modelov za umetno tvorjenje sintetičnih podatkov. Testirali smo ga na treh nalogah uvrščanja besedil in z njegovo uporabo izboljšali izhodiščen rezultate. Predstavili smo več metod ocenjevanja kvalitete umetnih množic ter predstavili, kako ugotovitve uporabimo za razvoj novih pristopov tvorjenja umetnih primerkov. Razvitih in testiranih je bilo več tehnik umetnega tvorjenja, od katerih izstopa dodajanje pogostih besed v ukazni poziv, kar bistveno izboljša rezultate v primeru, ko imamo na voljo tako majhno množico označenih, kot tudi veliko množico neoznačenih primerkov. Najboljše rezultate smo dosegli z združevanjem umetno tvorjenih podatkov in LLM-označenih primerkov iz velike množice neoznačenih primerkov. Glavni prispevki naloge vključujejo implementacijo ogrodja in razvite strategije tvorjenja, ki smo jih vrednotili z različnimi metrikami na več scenarijih.
Ključne besede
veliki jezikovni modeli, umetno tvorjeni podatki, obdelava naravnega jezika, uvrščanje besedil, podatkovne množice
large language models, synthetic data, natural language porcessing, text classification, datasets
Avtomatska ekstrakcija podatkov iz računov (Gregor Ažbe)
Automatic invoice data extraction
V tem magistrskem delu se osredotočamo na problem prepoznavanja podatkov z računov, ki so ključni administrativni dokumenti v poslovanju podjetij. Podjetja potrebujejo podatke računov v digitalni obliki, da jih lahko računalniško obdelujejo. Kljub naraščajoči uporabi elektronskih računov so ti večinoma v formatu PDF in ne vsebujejo strukturiranih metapodatkov, kar otežuje avtomatizirano ekstrakcijo podatkov. Ročno prepisovanje podatkov je zamudno in nagnjeno k napakam, zato je avtomatizacija tega procesa izjemnega pomena.
V delu smo implementirali, opisali in primerjali uspešnost treh različnih pristopov za avtomatsko ekstrakcijo podatkov z računov. Prvi pristop temelji na klasičnih metodah strojnega učenja, kjer smo preizkusili več modelov, vključno z odločitvenimi drevesi, naključnimi gozdovi, metodami podpornih vektorjev in drugimi. Drugi pristop temelji na grafovskih nevronskih mrežah (GNN), tretji pa na pristopu s predlogami, ki ne uporablja strojnega učenja. Značilke za strojno učenje so vključevale pozicijske podatke, kot so položaj, velikost očrtanega pravokotnika in številka strani, ter besedilne značilke, kot so prisotnost določenih besed v okolici in število določenih znakov v besedi.
Naš pristop s klasičnim strojnim učenjem je dosegel najboljše rezultate, saj smo z uporabo ekstremno naključnih dreves dosegli F1 = 0,89. Pristop z GNN je dosegel F_1 = 0,87, medtem ko je pristop s predlogami dosegel F1 = 0,70.
Ekstremno naključna drevesa so se izkazala za najprimernejši pristop, saj je poleg najvišje uspešnosti njihova prednost tudi v nižji računski zahtevnosti in v tem, da v primerjavi z GNN za učenje potrebujejo manj učnih primerov.
V primeru, da bi se pojavila potreba po dodajanju novih polj, bi morali pri pristopih s strojnim učenjem pridobiti veliko računov z novim poljem za učenje in ustrezno popraviti modele. Pri pristopu s predlogami pa bi zadoščal samo en račun z novim poljem za vsak tip računa, s katerim bi popravili ustrezno predlogo. V nadaljnjem delu bi lahko raziskali dodatne pristope, ki bi omogočali hitro učenje na podlagi le nekaj računov ali pa različne pristope z ANN, saj ti običajno zagotavljajo višjo uspešnost.
Profiliranje uporabnikov in dinamično priporočanje produktov z vektorskimi bazami (Denis Derenda Cizel)
User profiling and dynamic product recommendation with vector databases
Količina podatkov se iz dneva v dan povečuje. Z namenom filtriranja velikega toka podatkov so bili razviti različni priporočilni sistemi, ki izvajajo preslikavo med uporabniki in predmeti priporočanja z namenom čim hitrejše interakcije med njimi. V magistrskem delu se posvetimo priporočilnim sistemom na podlagi sodelovanja in delovanje preverimo na podatkih o telekomunikacijskih storitvah uporabnikov. Priporočanje ovrednotimo z različnimi merami uspešnosti. Sodelovalno priporočanje z namenom izboljšanja priporočanja nadgradimo v različne hibridne pristope. Hibridni pristop z dodatkom demografskih podatkov pravilno predlaga 85 odstotkov uporabniških priporočil. Z upoštevanjem zaporedja interakcij je mogoče pravilno napovedati naslednjo uporabniško storitev v 74 odstotkih. Implementirano je bilo tudi shranjevanje vektorskih predstavitev v vektorsko bazo, ki naredi priporočilni dostop bolj dostopen za uporabo.
Ključne besede
priporočilni sistemi, profiliranje, vsebinsko osnovana metoda, metoda izbiranja s sodelovanjem, vektorska baza
Avtomatska prepoznava in digitalizacija obrazcev (Robert Tovornik)
Automatic recognition and digitalisation of forms
Celostna digitalna transformacija organizacije zahteva digitalizacijo obstoječih in novo nastajajočih podatkov. Organizacije, ki podatke zajemajo preko vnosnih obrazcev v fizični papirni obliki, kot na primer večina zdravstvenih organizacij, morajo za pospešitev digitalizacije digitalizirati tudi vnosne obrazce. Digitalizacija kompleksnih vnosnih obrazcev je nepotrebno časovno zahtevna, saj je proces mogoče avtomatizirati. V sodelovanju s podjetjem Better, ki že omogoča kreiranje digitalnih obrazcev, smo razvili programsko rešitev za avtomatsko prepoznavo in digitalizacijo obrazcev. Programska oprema, razvita za delovanje v oblaku, uporablja tehnologijo optičnega prepoznavanja znakov, polj za vnos besedila, potrditvenih in izbirnih vnosnih polj in razpredelnic ter povezovanje podatkov za natančno prepoznavanje in digitalizacijo različnih vrst obrazcev. Vključen je izbirni korak človekovega posredovanja, ki omogoča prilagoditev želenih rezultatov. Evalvacija delovanja posameznih komponent izkazuje visoko učinkovitost in natančnost delovanja primerljivo z drugimi komercialnimi ponudniki storitev, ki celostne rešitve ne ponujajo. Povratne informacije izkazujejo večjo produktivnost in časovni prihranek pri procesu digitalizacije obrazcev.
Samonadzorovano odkrivanje anomalij v produkcijskih dnevniških zapisih (Tomaž Martinčič)
Self-supervised anomaly detection in production log streams
Rešitve za avtomatsko odkrivanje anomalij v sistemskih dnevniških zapisih so potrebne za učinkovito analizo in interpretacijo ogromnih količin ustvarjenih podatkov dnevnikov, odkrivanje skritih vzorcev in napovedovanje sistemskih anomalij, izboljšanje učinkovitosti delovanja, zagotavljanje varnosti sistema in zmanjšanje možnih izpadov. V zadnjem času je prišlo do razvoja na področju samodejnega odkrivanja nepravilnosti z uporabo metod strojnega učenja.
V tem delu smo razširili na tem področju dobro znano metodo LogBERT v hierarhični transformator z vključitvijo prednaučenega jezikovnega modela za pridobitev semantičnih vložitev predlog dnevniških zapisov. S tem zagotavljamo bogatejše informacije in se izognemo težavam novih predlog, s katerimi se sooča izvirna metoda LogBERT. Predstavljamo novo metodo, imenovano SemLogBERT.
Ugotovili smo, da rezultati, predstavljeni v večini modernih metod, močno precenjujejo njihovo učinkovitost. LogBERT in SemLogBERT smo ovrednotili v bolj realističnem scenariju, kjer smo izboljšali rezultate na nekaterih izmed standardnih primerjalnih podatkovih zbirk na tem področju.
Ključne besede
Obdelava naravnega jezika, odkrivanje anomalij, produkcijski dnevniški zapisi, strojno učenje, samonadzorovano strojno učenje
natural language processing, anomaly detection, production logs, machine learning, self-supervised learning
Komentar
V sodelovanju s somentorjem iz industrije - mag. Álvaro García Faura (XLAB)
Uporaba sodobnih pristopov obdelave naravnega jezika je ključna, da lahko pravna industrija obdeluje velike količine besedil in zagotavlja učinkovite storitve. Pravne raziskave so področje, na katerega imajo ti pristopi največji vpliv, saj pravnikom omogočajo hitrejše iskanje ustrezne zakonodaje in sodne prakse. S ciljem zagotoviti povzetke dolgih pravnih besedil v delu obravnavamo avtomatsko povzemanje slovenskih sodnih odločb.
Predlagamo GloBerto-Sum, ekstraktivni pristop, ki temelji na nedavno predstavljenih slovenskih vnaprej naučenih jezikovnih modelih. Da lahko obravnava daljše dokumente, se naš pristop zanaša na strukturo sodnih odločb. Naučen je na mehkih oznakah, kar ublaži težave, ki jih prinaša visoko razmerje med številom povedi v dokumentih in povzetkih. GloBerto-Sum dodatno združimo z abstraktivnim modelom - tako pridobljen hibridni pristop je zmožen generirati povzetke s parafriziranjem.
Rezultati kažejo, da naši pristopi generirajo povzetke, ki so po ustreznosti na ravni ročno napisanih, a so lahko nekoliko manj koherentni in vsebujejo več redundantnih informacij. Kljub temu menimo, da z našim delom pokažemo možnost uporabe predlagane metodologije za tvorjenje povzetkov, ki pravnikom omogočajo hitrejši pregled pravnih besedil.
Avtomatska gradnja korpusa in ekstrakcija relacij v slovenščini (Miha Štravs)
Automatic corpus construction and relation extraction for Slovene
Iskanje relacij med entitetami v besedilu je področje obdelave naravnega jezika. Pri iskanju relacij želimo v stavku: "Ljubljana je glavno mesto Slovenije" odkriti, da med entitetama Ljubljana in Slovenija nastopa relacija glavno mesto.
V zaključnem delu smo najprej naredili pregled metod za učenje modelov za napovedovanje relacij. Nato smo si izbrali tri metode z različnimi pristopi za učenje modelov, ki napovedujejo relacije. Metodo s povratno nevronsko mrežo z dolgim kratkoročnim spominom, metodo z vložitvami BERT in metodo RECON, ki uporabi grafovsko nevronsko mrežo s pozornostjo. Za učenje modelov smo uporabili slovenski korpus, ki smo ga polavtomatsko generirali iz besedil slovenske Wikipedije. Naučene modele smo nato testirali na testnem korpusu besedil slovenske Wikipedije in testnem korpusu člankov strani 24ur.com. Na testnem korpusu slovenske Wikipedije so vse tri metode dosegle visoke priklice in točnosti, najbolje se je odrezala metoda RECON. Veliko slabše rezultate so dosegle na testni množici člankov 24ur.com, kjer se je še najbolje izkazala metoda z vložitvami BERT, ko je uporabila vložitve CroSloEngual.
Ključne besede
ekstrakcija relacij, ekstrakcija informacij, globoko učenje, grafovske mreže pozornosti, BERT, LSTM
relation extraction, information extraction, deep learning, graph attention networks , BERT, LSTM
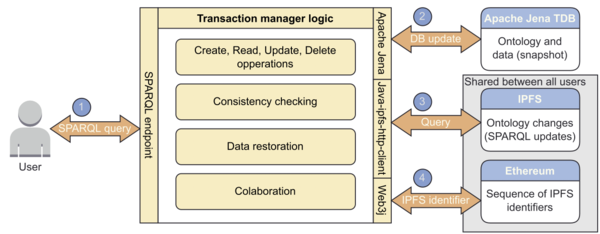
Integracija verige blokov in tehnologij semantičnega spleta (Domen Gašperlin)
Integration of blockchain and semantic web technologies
Cilj semantičnega spleta je standardizacija izmenjave podatkov na spletu. Za njihovo predstavitev se uporabljajo ontologije. Gradnja ontologije je cikličen proces, ki zahteva usklajevanje in koordinacijo njenih sprememb s strani strokovnjakov z različnih področij. Za to je ključno sledenje, od kod so prišle spremembe in kdo jih je naredil. Prav tako s spreminjanjem ontologije ne smemo porušiti njene konsistentnosti. Namen dela je izboljšanje procesa gradnje ontologije z razvojem rešitve za njeno upravljanje in distribucijo. Rešitev poskrbi, da se s spremembami ontologije ne poruši njena konsistentnost. Za svoje delovanje uporablja tehnologije semantičnega spleta in verige blokov. Tehnologije semantičnega spleta se uporablja za učinkovito poizvedovanje in spreminjanje podatkov, za varno shrambo ontologij in sledljivosti njihovih sprememb pa se uporablja verige blokov. Na koncu je na podmnožici ontologije DBpedia evalvirano, kakšna je cena uporabe rešitve in kakšna je njena časovna zahtevnost v primerjavi s knjižnico Apache Jena. Rezultati pokažejo, da je rešitev počasnejša, a primerljiva, kot če bi se uporabilo zgolj knjižnico Apache Jena. Rešitev je z določenimi spremembami primerna tudi za implementacijo za druge tipe podatkovnih baz.
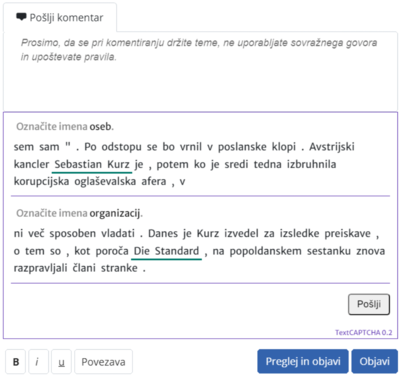
Preprečevanje neželenih komentarjev za spletne novice s pomočjo tehnik za procesiranje naravnega jezika (Martin Čebular)
Preventing unwanted comments to online news articles using natural language processing techniques
Completely Automated Public Turing test to tell Computers and Humans Apart (v nadaljevanju CAPTCHA) je test, katerega cilj je ločiti človeškega uporabnika od računalnika. Na spletu se test CAPTCHA navadno pojavi ob obrazcu, kot zaščita pred samodejnim izpolnjevanjem in oddajanjem obrazca. Kot najbolj znano obliko testa CAPTCHA omenimo test, v okviru katerega je reševalcu podana slika s popačenim besedilom, reševalčeva naloga pa je razpoznati črke ali besede z dane slike.
V magistrskem delu se posvetimo testom oziroma nalogam CAPTCHA v tekstovni obliki. Zasnujemo in implementiramo sistem CAPTCHA, katerega naloge temeljijo na tehnikah obdelave naravnega jezika. Predstavimo dva tipa tovrstnih nalog CAPTCHA: naloge na podlagi prepoznavanja imenskih entitet in naloge na podlagi razreševanja koreferenčnosti. Sistem CAPTCHA zasnujemo razširljivo, kar omogoča enostavno vpeljavo novih tipov nalog vanj. Implementiramo tudi odjemalca CAPTCHA, uporabniški vmesnik, ki ga lahko umestimo v spletni obrazec in reševalcem omogoča reševanje nalog. Uporabo sistema CAPTCHA skupaj z odjemalcem prikažemo na primeru integracije, izdelanem v okviru magistrskega dela.
Uporabo demonstriramo tudi z umestitvijo odjemalca CAPTCHA v obrazec za oddajo komentarja na spletnem portalu RTVSLO.si. Implementirani sistem skupaj z odjemalcem omogoča celostno izvedbo postopka verifikacije človeške interakcije uporabnikov. Evalviramo njegovo učinkovitost in skalabilnost, dostopnost odjemalca CAPTCHA slepim in slabovidnim uporabnikom, ter potencialne možnosti za gradnjo novih učnih množic iz zbranih podatkov, ki nastanejo z uporabo sistema.
Ključne besede
CAPTCHA, dokaz o človeški interakciji, prepoznavanje imenskih entitet, odkrivanje koreferenčnosti
CAPTCHA, human-interaction proof, named entity recognition, coreference resolution
Avtomatska ekstrakcija podatkov o zaposlenih s spletišč podjetij (Matej Koplan)
Automatic extraction of employee data from corporate websites
V tem delu se ukvarjamo s problemom ekstrakcije seznama oseb s poljubnega spletišča. V ta namen implementiramo spletnega pajka za identifikacijo potencialnih podstrani z osebami in ekstraktor podatkov, ki s poljubne spletne strani izvleče podatke o osebah.
Pokažemo, da osnovne metode, kot so primerjava imena s seznamom imen, ne dosežejo sprejemljive natančnosti. Pokažemo, da je analiza strukture seznama in prenos odkritega znanja ključna metoda za izboljšavo rezultatov do stopnje, kjer dosežemo sprejemljiv nivo natančnosti. S pomočjo tega pristopa smo izboljšali F1 mero za 50 % na razvojni in za 35 % na skriti testni množici.
Ključne besede
splet, ekstrakcija podatkov, avtomatska ekstrakcija podatkov s spleta, fokusirani spletni pajki, strukturirani podatki, nestrukturirani podatki
web, data extraction, automatic web data extraction, focused webcrawlers, structured data, unstructured data
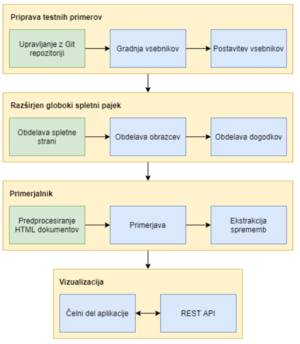
Identifikacija in povezovanje razlik med izvorno kodo in čelnim delom tekom razvoja spletne aplikacije (Jošt Gombač)
Identification of changes between source code and frontend during development of a Web application
Tekom razvoja spletnih aplikacij se lahko zgodi, da katero izmed prej implementiranih funkcionalnosti nehote spremenimo. Pravilnost delovanja programa skozi celoten potek razvoja navadno preverjamo z regresijskimi testi. Priprava teh lahko terja velik časovni vložek. Dodatno pa jih je potrebno prilagoditi spremembam, ki so pričakovane. Kot odgovor tej problematiki smo implementirali programsko orodje, s pomočjo katerega bo možno zaznati razlike med dvema različicama iste spletne aplikacije.
Naš pristop vključuje uporabo spletnega pajka, ki je sposoben odkrivati dinamično generirano vsebino preko uporabniških akcij, kot je izpolnjevanje obrazcev in klikanje elementov. Na podlagi pridobljenih HTML dokumentov nato upoštevajoč drevesno strukturo ugotovi medsebojne razlike. V namen interpretacije ugotovljenih sprememb smo implementirali spletno aplikacijo, ki kronološko prikazuje vse razlike med uveljavitvami v Git repozitoriju.
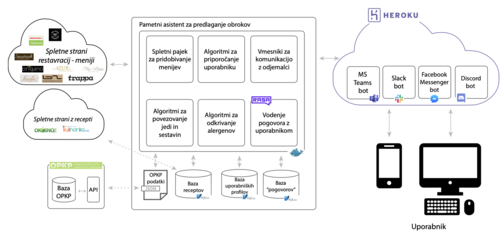
Pametni asistent za predlaganje obrokov (Janez Eržen)
Smart assistant for suggesting meals
Izdelava pametnih asistentov zahteva implementacijo sistemov za zajem podatkov, prepoznavanje namena, ekstrakcijo podatkov, priporočilne sisteme ipd. V magistrskem delu smo izdelali celostnega pametnega asistenta za predlaganje obrokov, bolj podrobno pa smo se osredotočili na prepoznavanje alergenov in hranil vsebovanih v jedeh glede na delno strukturirane podatke o menijih na spletnih straneh restavracij. Z namenom reševanja omenjenega problema smo razvili algoritem za ločevanje besedila menija na posamezne jedi vsebovane v njem, algoritem za detekcijo alergenov iz besedila na podlagi pravil ter algoritem za detekcijo alergenov z uporabo nevronske mreže.
Omenjene algoritme smo uporabili za implementacijo pametnega asistenta, ki uporabniku omogoča obogaten in prilagojen prikaz dnevno pridobljenih jedilnikov s spleta. Asistent je integriran v različne sisteme sporočanja (Microsoft Teams, Discord, Slack ter Facebook Messenger), pogovor z uporabnikom pa poteka v slovenskem jeziku.
S preizkusom asistenta v praksi smo pokazali, da uporabnikom olajša izbiro menija ali restavracije za dnevno kosilo. Algoritem za avtomatsko ekstrakcijo alergenov z uporabo nevronske mreže dosega uspešnost 68% (ocena F1), kar je dovolj uporabno za opozarjanje uporabnika na možno vsebnost alergenov v jedi, je pa smiselno, da uporabnik to opozorilo asistenta dodatno preveri pri osebju restavracije.
Ključne besede
pametni asistent, obdelava naravnega jezika, ekstrakcija podatkov s spleta, prehrana, priporočanje uporabniku
chatbot, natural language processing, web scraping, nutrition, user recommendation
Napovedovanje glasovanj strank v Evropskem parlamentu (Miha Nahtigal)
Predicting Roll-Call Voting of Political Parties in European parliament
Evropski parlament je politično telo, ki že dolgo časa razdvaja javnost. Njegovi nasprotniki po eni strani trdijo, da je tako politično in kulturno heterogen organ nezmožen učinkovitega delovanja, po drugi strani pa naj bi evropski poslanci hitro izgubili stik s svojimi volivci ter glasovali predvsem tako, kot jim to naročijo vodje skupin. Zanimalo nas je, če evropski poslanci glasujejo dovolj avtomatično in predvidljivo, da bi lahko rezultate glasovanj uspešno napovedovali z modelom strojnega učenja. Da smo zmanjšali časovno kompleksnost smo se odločili za napovedovaje rezultatov glasovanj po političnih strankah. Najprej smo implementirali spletne pajke, s katerimi smo pridobili čim več rezultatov glasovanj in z njimi povezanih podatkov. Iz teh smo nato z interdisciplinarno kombinacijo metod podatkovnega rudarjenja ter strokovnega geopolitičnega znanja izluščili značilke in zgradili model.
Rezultati so pokazali približno 80% uspešnost napovedovanja rezultatov glasovanj (uteženi oceni f1 in roc-auc). Napovedovanje je bilo bistveno bolj uspešno pri strankah s proevropsko,liberalno in globalistično politično usmeritvijo kot to velja za evroskeptične, ekonomsko socialne in nacionalistične stranke. S tem smo dodatno podprli tezo o obstoju in pomembnosti nove nacionalistično-globalistične politične delitve. Poleg tega predstavlja problem tudi razred vzdržanih glasovanj, ki ga je težko napovedati že s pomočjo človeške inteligence.
Ključne besede
napovedovanje, glasovanja, politične stranke, Evropski parlament
predicting, Roll-Call votes, political parties, European parliament
Primerjava orodij za vizualizacijo in preiskovanje omrežij (Didka Dimitrova Birova)
Zaradi povečevanja količine in kompleksnosti podatkov uporabniki vse težje učinkovito preučujejo velike množice podatkov. Podatki so med seboj povezani in posledično lahko množico podatkov predstavimo in vizualiziramo v obliki omrežja (socialna, biološka, svetovni splet). Glavni namen vizualizacije je učinkovito posredovati in predstaviti podatke s pomočjo vizualne percepcije ter predvsem olajšati raziskovanje podatkov oziroma omrežja. Za analizo in prikaz omrežij obstaja množica orodij - nekatera pokrivajo področje analize kot tudi prikaza, specializirana orodja pa se osredotočajo samo na analizo ali samo na vizualizacijo, oziroma so lahko specializirana za določeno domeno (npr. socialna omrežja).
V okviru naloge bi bilo potrebno narediti primerjavo in evaluacijo orodij za vizualizacijo omrežij – kakšne so omejitve, performance, možnosti za razširitev in dopolnjevanje obstoječih orodij.
Označevanje imenskih entitet v pravnih besedilih (Matic Di Batista)
Odkrivanje podatkov iz besedil velja za eno izmed aktualnih podpodročij v okviru obdelave tekstovnih podatkov. Za slovenski jezik še nimamo dovolj prilagojenih pristopov ali ogromnih podatkovnih množic iz katerih bi lahko zgradili praktično uporabne metode za odkrivanje entitet. Namen diplomske naloge ja zato izdelava orodja, ki bo znalo odkrivati imenske entitete v slovenskih besedilih.
Kandidat naj pregleda obstoječe metode za odkrivanje entitet v besedilih in jih prilagodi za delo s slovenskim jezikom. Pri tem naj primerja njihovo delovanje in razišče morebitne probleme, ki so posledica sintakse in pravil v slovenščini. Nazadnje naj predlaga nov nabor značilk za učenje modelov in razvito metodo testira nad lastno izdelano podatkovno množico.
Ključne besede
ekstrakcija podatkov iz besedil, razpoznavanje entitet, tekstovno rudarjenje
Komentar
Usmerjanje in pomoč pri mentorstvu prof. dr. Marka Bajca. Gre za diplomsko nalogo enake stopnje bolonjskemu magisteriju.
Kontekstualno ujemanje in iskanje na modelu spletne oglasne deske (Vasja Laharnar)
Spletne oglasne deske so specializirani iskalniki, ki lahko namesto dokumentov (npr. spletne strani, slike, besedila), indeksirajo uporabnike sistema. Primer so socialni iskalniki, ki ne vrnejo neposrednega odgovora, ampak se poizvedba pošlje uporabniku, ki ga sistem spozna za relevantnega in nato le ta odgovori. Takšni iskalniki morajo torej bolj upoštevati uporabniške profile in njihove kontekste.
V okviru diplomske naloge naj kandidat izdela spletno storitev, ki bo omogočala objavljanje besedil in njihovo iskanje. Pri tem naj kandidat preuči korake procesiranja besedil za potrebe splošnega indeksiranja. Poleg tega naj pri implementaciji iskanja in primerjanja besedil upošteva tudi semantične podatke, k jih pridobi iz besedil ali profilov uporabnikov. Nazadnje naj izdelano storitev testira na domeni študijskih praks, kjer v sistemu sodelujejo profesorji, študenti in podjetja.
Semantično zajemanje podatkov iz predefiniranih virov (Alan Rijavec)
Izdelajte komponento za zajem podatkov iz spletnih virov. Komponenta naj bo zasnovana modularno, tako da bo dodajanje novega vira zahtevalo le implementacijo določenih vmesnikov. Vhodi in rezultati naj bodo semantično označeni, tako da bo komponenta zmožna sama izvajati klice funkcij in sestavljati rezultate v obliki RDFS ali drugega semantičnega zapisa.
Pridobivanje konteksta z uporabo spletnih brskalnikov (Marko Jurinčič)
Današnje inteligentne aplikacije morajo za svoje delovanje beležiti in uporabljati kontekst uporabnika. Zamislite si pristop, kako čim bolj natančno modelirati kontekst določenega uporabnika. Cilj je, da iz ugotovljenih virov pridobite trenutno relevantne teme (besede) za uporabnika. Uporabljate lahko čim več virov, ki jih lahko: na primer zvok, slika, video uporabnika, pisanje. Primer vašega dela: Implementacija orodne vrstice v iskalniku Firefox, ki ima možnost beleženja in shranjevanja različnih parametrov (čas na določeni spletni strani, interakcija z drugimi programi). Podobna orodna vrstica je implementirana znotraj Lemur Project-a, ki si gradi t.i. query-log. Mogoče tudi beleženje konteksta preko aplikacije pametnega telefona.
Ključne besede
kontekst, vtičnik, podatkovno rudarjenje
Komentar
Usmerjanje in pomoč pri mentorstvu prof. dr. Marka Bajca. Gre za diplomsko nalogo enake stopnje bolonjskemu magisteriju.